
The term “backwards design” is often applied to curriculum design. If you want your students to learn a particular thing, you start with identifying what that outcome should look like at the end of the semester. Then you design your class backwards from that outcome, to make sure your students have a way to get there.
I think we should be talking more about backwards design when when it comes to statistics and the design of experimental and observational research.
Journalists call the key passage of each story a “nut graf.” Shouldn’t we have a “nut fig” for each experiment, and know what the axes and statistical tests will be before we run an experiment?I see a lot of papers that dance around the key result, that can’t be tested directly because there isn’t enough statistical power, or the wrong experimental design. Backwards planning can minimize this problem. Knowing what your “nut fig” is — before you get to work — is key.
For me, a new experiment begins with the figure. And when I’m writing it up, I start with the same figures that I imagined up front. (Some of the best grants I’ve seen, by the way, have a set of “nut figs” for each experiment, showing the range of possible results and how they would address the central aims of the proposal.)
Here’s an example. Several years ago I was wondering about how ant colonies decide how many soldiers they want to make. Maybe some species have a higher investment into soldier production than other species? I also wanted to know if any differences among species were explained by the body size of the ants.
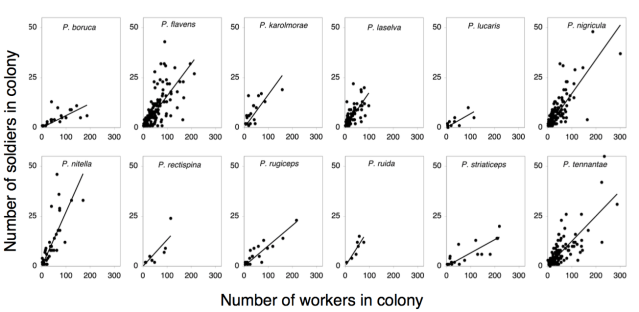
I figured it would take two figures to answer these questions. First, I imagined a figure that had a lot of panels — one for each species — looking at the relationship between the number of workers and the number of soldiers, with each variate in the plot representing a whole colony that was collected in the field.
Here’s what that picture looked like, once I wrote the paper:
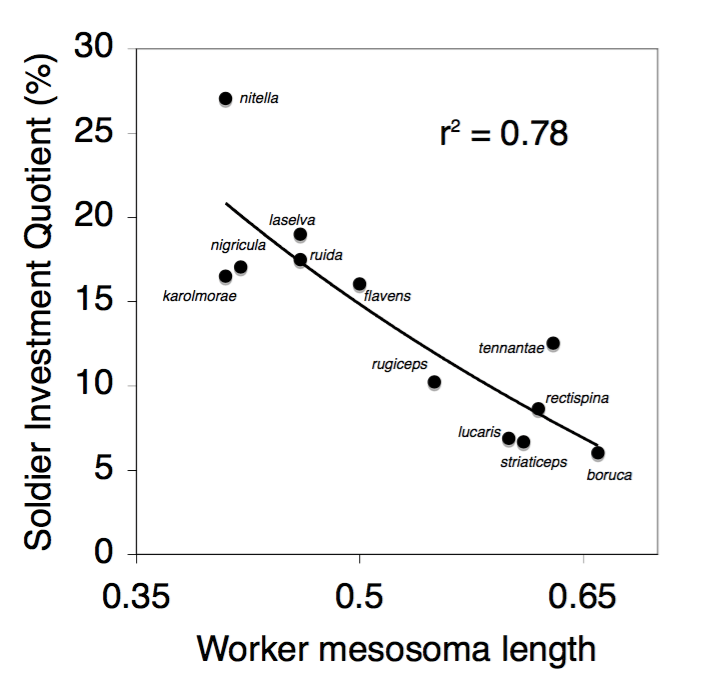
The second figure, to ask about whether interspecific differences are explained by body size, has an x axis from data pulled from the first figure. I could simply take the slopes of each line as a variable, and compare to the body size of the workers. That’s what I imagined up front, and the figure at the top of the post is what I made
I think this made a really compelling paper, and demonstrated this discovery in a robust manner. (Here’s the post about that paper, by the way).
I think this was compelling and convincing because I identified specifically the result that I think would answer the question best, and then I designed the work to get at these data. (I didn’t do the stats in excel, though I could have come to think of it, and that’s how I built these figs).
Do you know what your x-axis and y-axis will be on the “nut fig” for your experiment before you collect data?
Of course, we don’t know what we’re going to find, which is why we do experiments! And oftentimes, the things we don’t expect are the ones that end up being the most interesting and useful. Nonetheless, when we are designing experiments to answer specific questions, shouldn’t we know precisely how we plan to test our central question?
I think senior scientists tend do do backwards planning, at least implicitly, all of the time, just as a result of experience and practicality. Not everybody makes a point to discuss backwards experimental design while training students. In the process of mentoring a student who is at the start of a project, a great question might be, “When you’re writing this up, what do you think the key figure will look like?”

Great post, Terry, spot on. I’ve been in both situations you mention: making the pre-planned “nut fig”, but also cursing my idiocy in not pre-planning one! Some time ago I wrote about this, although with a different slant more tightly related to writing than to experimental design: https://scientistseessquirrel.wordpress.com/2016/03/29/good-uses-for-fake-data-part-2/
Nice.
1. It is a REALLY compelling fig, or nut.
2. Statisticians are always begging researchers to come to them first, in the planning stages of experiments, so that the analysis can used in the design.
Really interesting – I know a couple of labs where this approach is de riguer – seems to work for them. I’m an “old dog” but never too old to learn new tricks so will try this in teh grant proposal I am currently struggling to write :-)
Good post. Students are often advised to write papers by starting with the key figures and building around them. But as you point out, the writing actually starts with the study design.
I did for Fox et al. 2017 (https://dynamicecology.wordpress.com/2017/08/28/__trashed-4/). And I did it again for an ongoing project, though the nut figure didn’t turn out compelling, perhaps because we weren’t able to run the experiment long enough.
Though I never had a name for them, nut figs help me organize almost all of my research. In fact, a nut fig that I generated is how I got sucked into the project that turned into my first publication. The nut fig is fig 2 and the empirical fig testing the hypotheses in the nut fig is fig 3 – both are here https://figshare.com/articles/Stickleback_pelvic_reduction/5598826.